Rolling upgrades?
In the previous post we deployed our Swarm service on the public cloud, Amazon EC2.
In this post, we will play a bit with Rolling upgrades, and use some visualization tools to see what's going on our Docker cluster.
Let's go!
Docker Visualizer
Before we install the Visualizer, let me explain the configuration of my "cluster":
it is currently composed of 4 machines with docker installation, called stratus-clay, swarm1, swarm2 and swarm3 for this exercise. I'll be using stratus-clay as the manager most of the time, unless stated otherwise, and swarm1, swarm2 and swarm3 as the workers (But remember, the manager can be a worker too ;))
To get started, we will install the Docker Swarm Visualizer as per the command below:
docker run -it -d -p 8080:8080 -e HOST=stratus-clay -v /var/run/docker.sock:/var/run/docker.sock manomarks/visualizer
Check the above URL if you need to use another port for the visualizer.
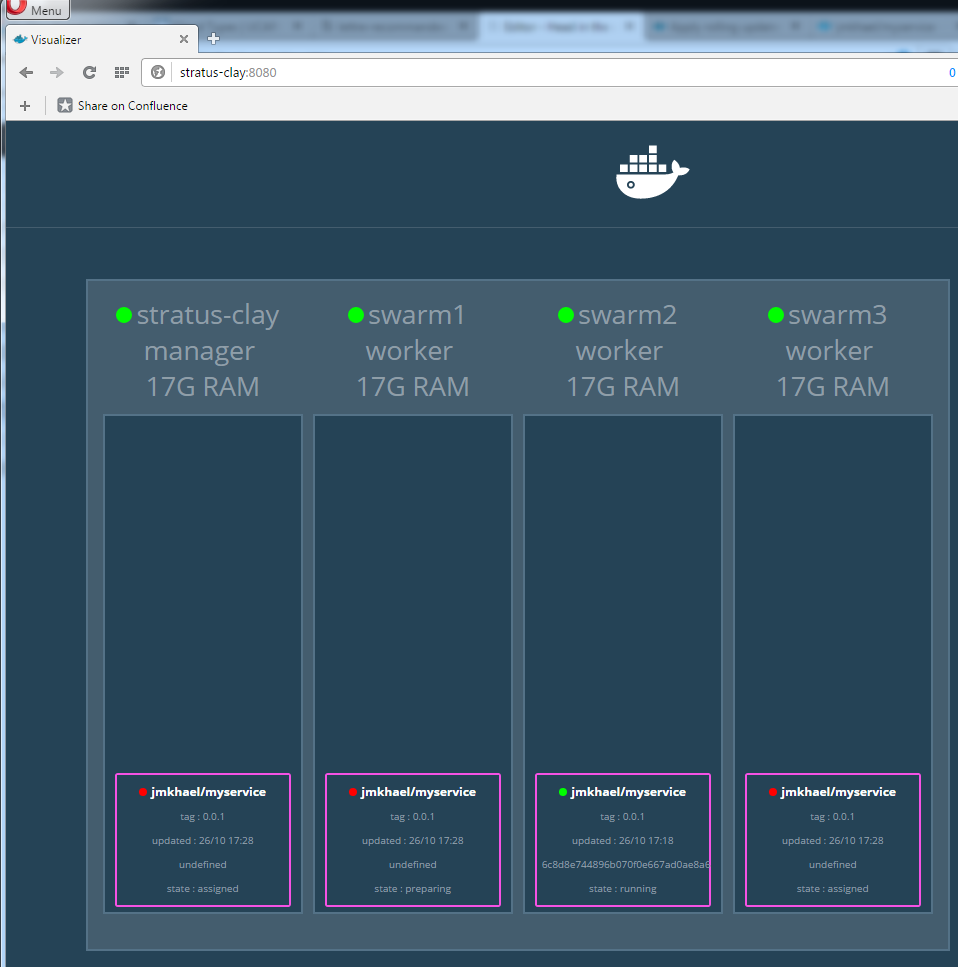
Once that done, open up in your browser http://stratus-clay:8080 and you should see an empty view.
Create our Greeters
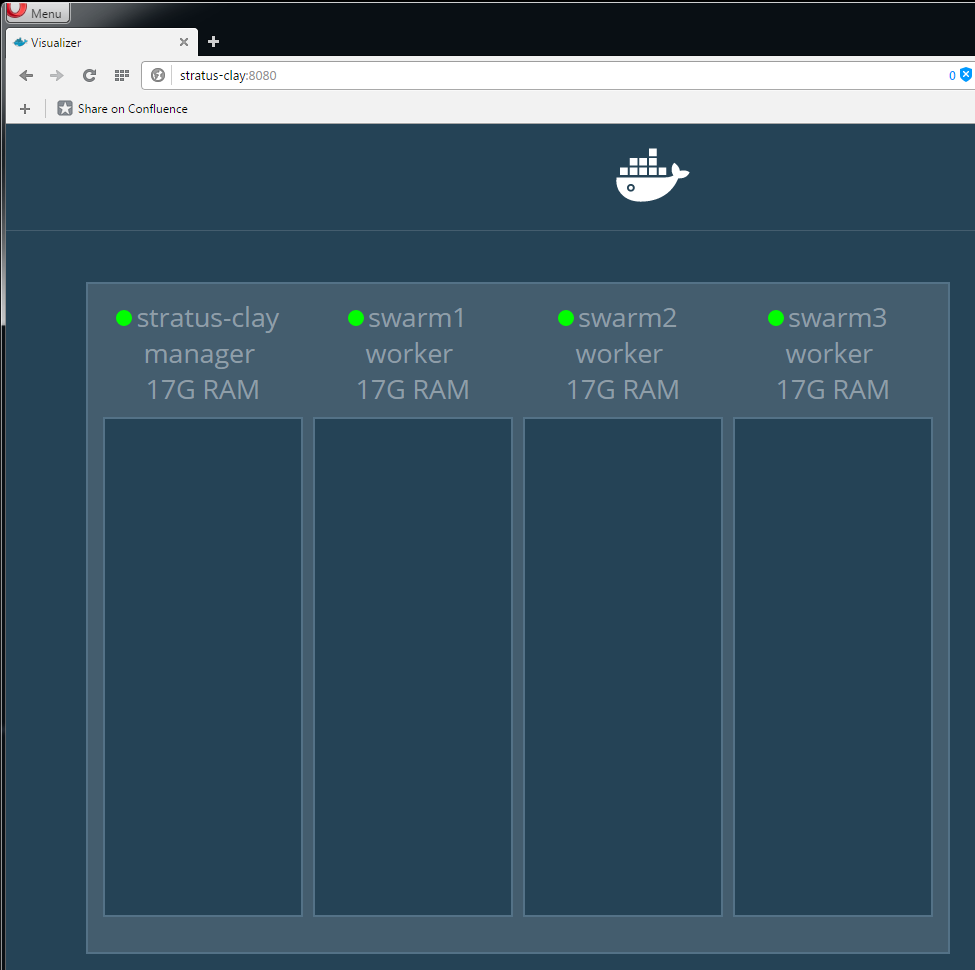
Ok, that's not bad. Time to create our Swarm and start seeing our master and nodes.
docker swarm init --advertise-addr 10.26.8.51
To add a worker to this swarm, run the following command:
docker swarm join \
--token SWMTKN-1-0kw0qfgwuvb0mvwikvyvkossujd9gdf3i3ov2onqxjq4q9jdiq-dcgjbrpj0pqnxywgmtpb4i5mk \
10.26.8.51:2377
Then copy and paste the command on the other machines, namely swarm1, swarm2 and swarm3
docker swarm join \ --token SWMTKN-1-0kw0qfgwuvb0mvwikvyvkossujd9gdf3i3ov2onqxjq4q9jdiq-dcgjbrpj0pqnxywgmtpb4i5mk \ 10.26.8.51:2377
Now, the Visualizer should show something like:
Neat. Time to create our service.
Do that by invoking:
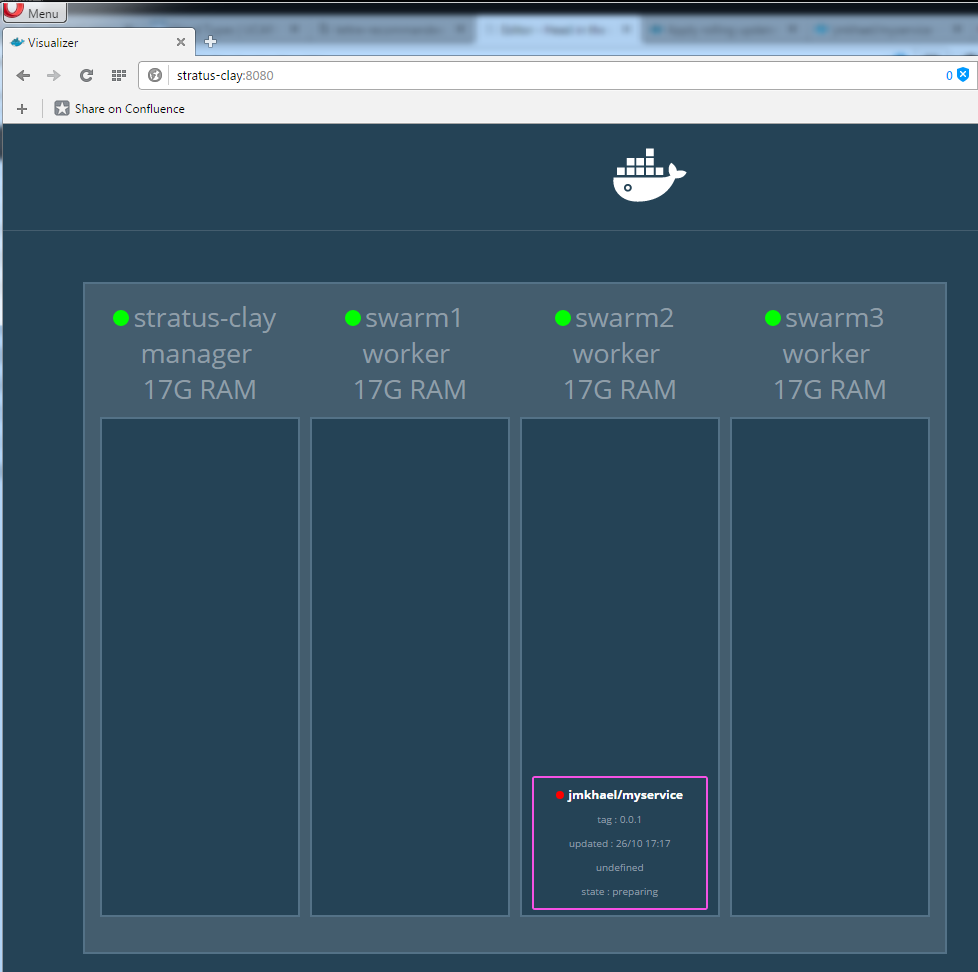
docker service create --publish 9000:5000 --name greeters jmkhael/myservice:0.0.1
If you are lucky, you'll notice that the Swarm is starting the image (pulling/deploying it):
and then move into a running state:
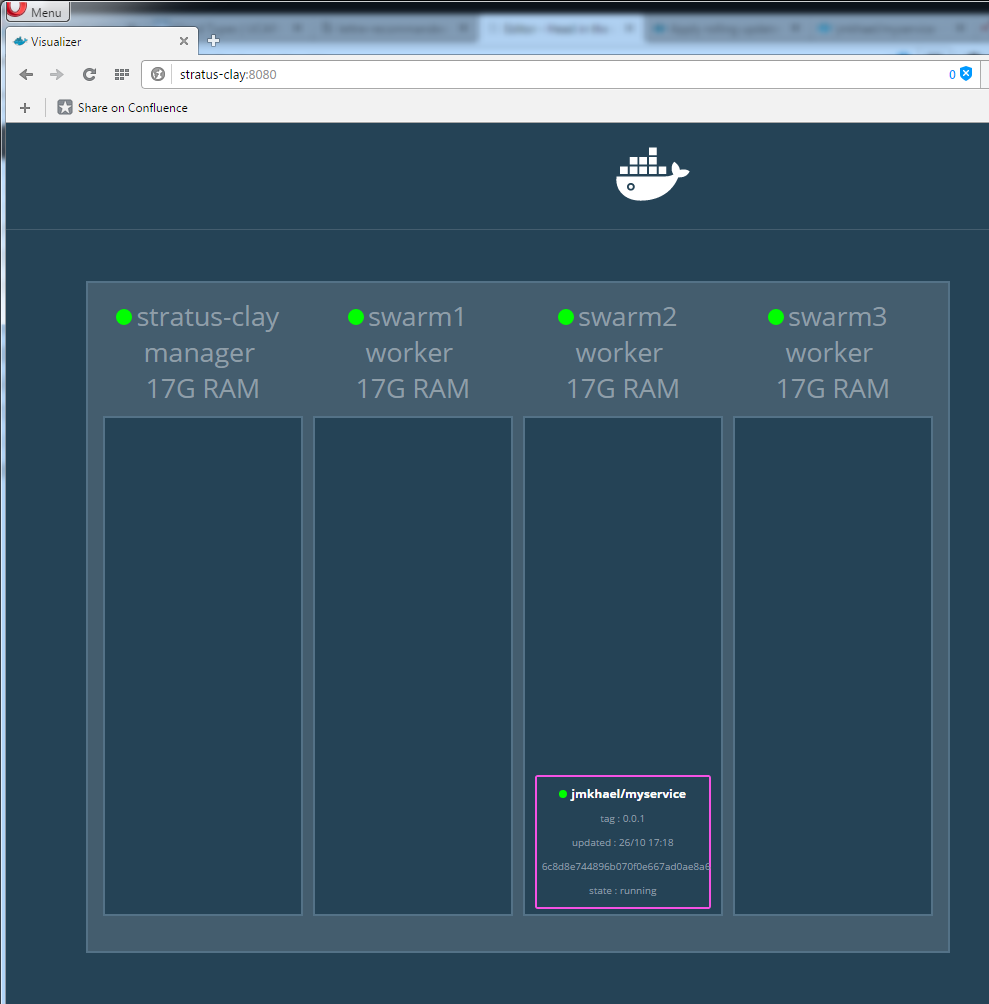
curl http://stratus-clay:9000
Hello, Docker world from 6c8d8e744896.
Let's do a first benchmark again, and see how performant is our service:
ab -n 100000 -c 30 http://stratus-clay:9000/ | grep "#/sec"
Requests per second: 2613.28 [#/sec] (mean)
Scaling our Greeters
Let's scale our service on 5 instances:
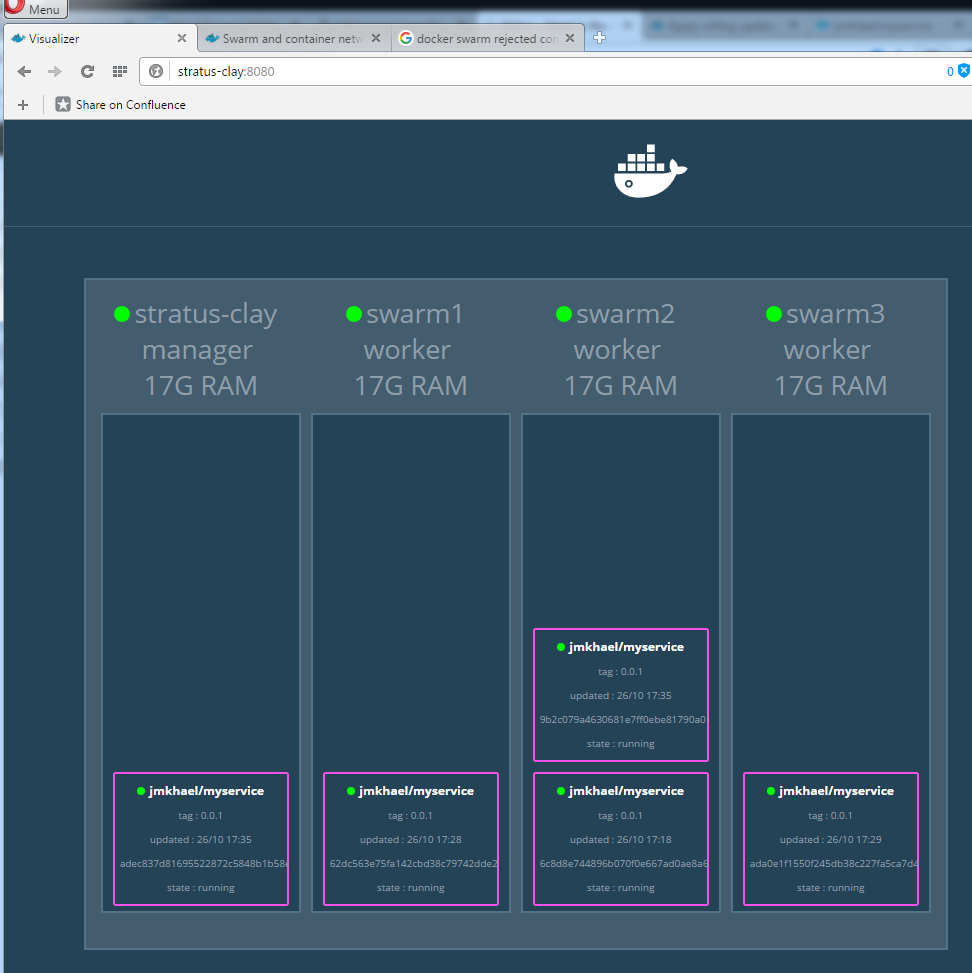
And perform our benchmark again:
ab -n 100000 -c 30 http://stratus-clay:9000/ | grep "#/sec"
Requests per second: 5488.99 [#/sec] (mean)
Not bad, for just performing some docker commands :)
Upgrading our Greeters
Ok, let's imagine that we want to deploy a newer (and of course better) image of our service. But of course we don't want our service to go offline. We would like to do a rolling upgrade, meaning that we want to upgrade our cluster, with no downtime for end users.
That also implies, that while our service is getting upgraded on some nodes, some other nodes are still handling user traffic. Our cluster will have potentially at the same time 2 versions of our service!
Enough talk. Let's see that in action now.
To test our service, let's simulate a user request, wanting a result in under 3 seconds, in an endless loop:
while true; do curl --connect-timeout 3 http://stratus-clay:9000/; sleep 1; done
Hello, Docker world from 9b2c079a4630.
Hello, Docker world from adec837d8169.
Hello, Docker world from ada0e1f1550f.
Hello, Docker world from 62dc563e75fa.
Hello, Docker world from 6c8d8e744896.
Hello, Docker world from 9b2c079a4630.
Hello, Docker world from adec837d8169.
Hello, Docker world from ada0e1f1550f.
Hello, Docker world from 62dc563e75fa.
Hello, Docker world from 6c8d8e744896.
....
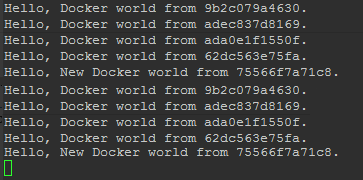
Here we see again the load balancing on different containers.
Let's upgrade the service with a new image which we built. The service will just reply with:
Hello New Docker world from <hostname>.
Keep the while loop going, and execute in another shell:
docker service update --image jmkhael/myservice:0.0.2 greeters
The upgrade procedure start by isolating one container at a time, upgrading it, then move to the next. We can also configure parallelism (but we won't :p)
The default upgrade config policy, makes it that the scheduler applies rolling updates as follows by default:
- Stop the first task. (aka. container)
- Schedule update for the stopped task.
- Start the container for the updated task.
- If the update to a task returns RUNNING, wait for the specified delay period then stop the next task.
- If, at any time during the update, a task returns FAILED, pause the update.
check Swarm rolling update tutorial for more details.
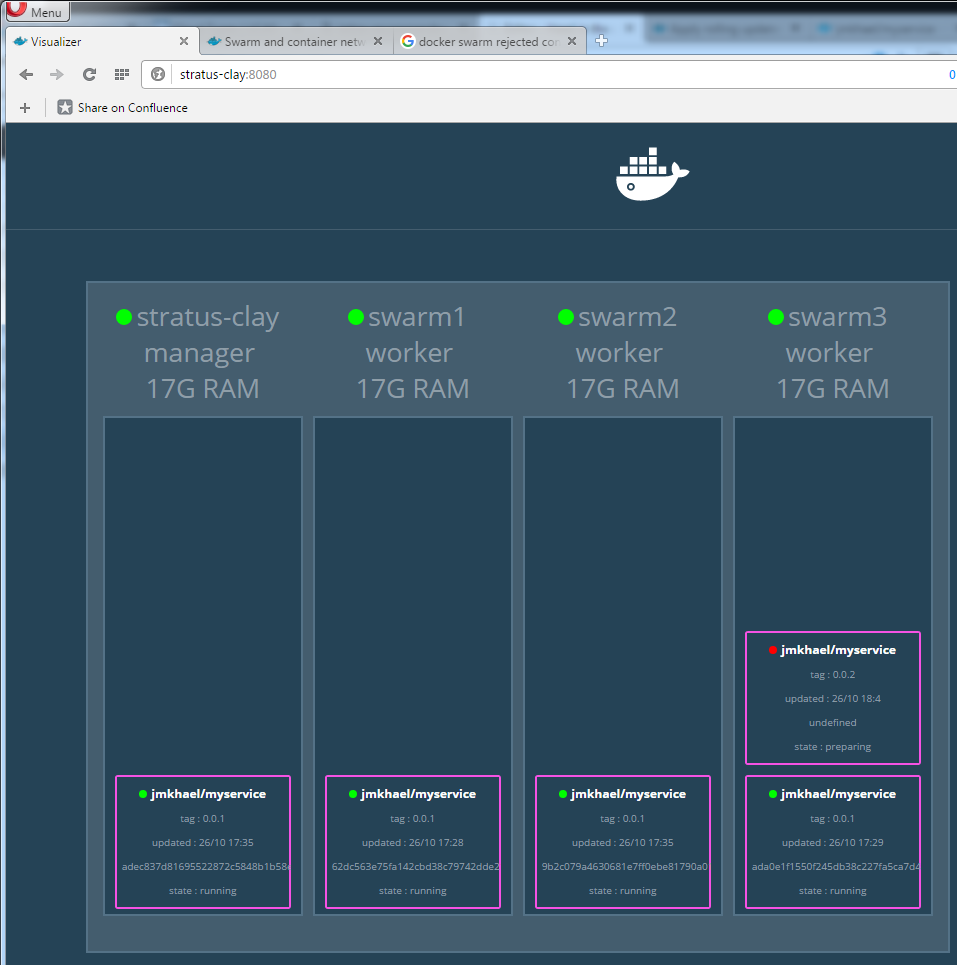
Meanwhile, our user can see the old or the new service transparently:
After a while, if everything goes according to plan, your cluster would be running the new version, and the client only 'sees' the new service.
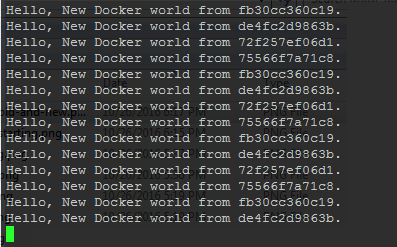
If Docker faces a problem, it applies the UpdateConfig/on failure strategy. To see what is set for our service we can do:
jmkhael@stratus-clay:~$ docker service inspect --pretty greeters
ID: 7safdv93fss4y3jii7broqg14
Name: greeters
Mode: Replicated
Replicas: 5
Placement:
UpdateConfig:
Parallelism: 1
On failure: pause
ContainerSpec:
Image: jmkhael/myservice:0.0.2
Resources:
Ports:
Protocol = tcp
TargetPort = 5000
PublishedPort = 9000
You can change that, via the flag. Check
--update-failure-action string Action on update failure (pause|continue) (default "pause")
Type docker service update --help for more things you can do.
Draining nodes
For this blog post, we will do one more thing. We will remove a node from the cluster, (imagine we want to upgrade the hardware/or whatever)
To do that, we drain the aforementioned node:
docker node update --availability drain stratus-clay
Then type:
docker node ls to see the state of the swarm:
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
2a60n3masa7caj3nwpx4ob6vw swarm2 Ready Active
5rwxxo6rlkzpod4huvj452ypm * stratus-clay Ready Drain Leader
5yofhm65wf61e38j56e2v0a6q swarm3 Ready Active
9fqyn7nhma3m0alc2jpqc11et swarm1 Ready Active
Let's try to isolate all the nodes, but keep one, and see what happens:
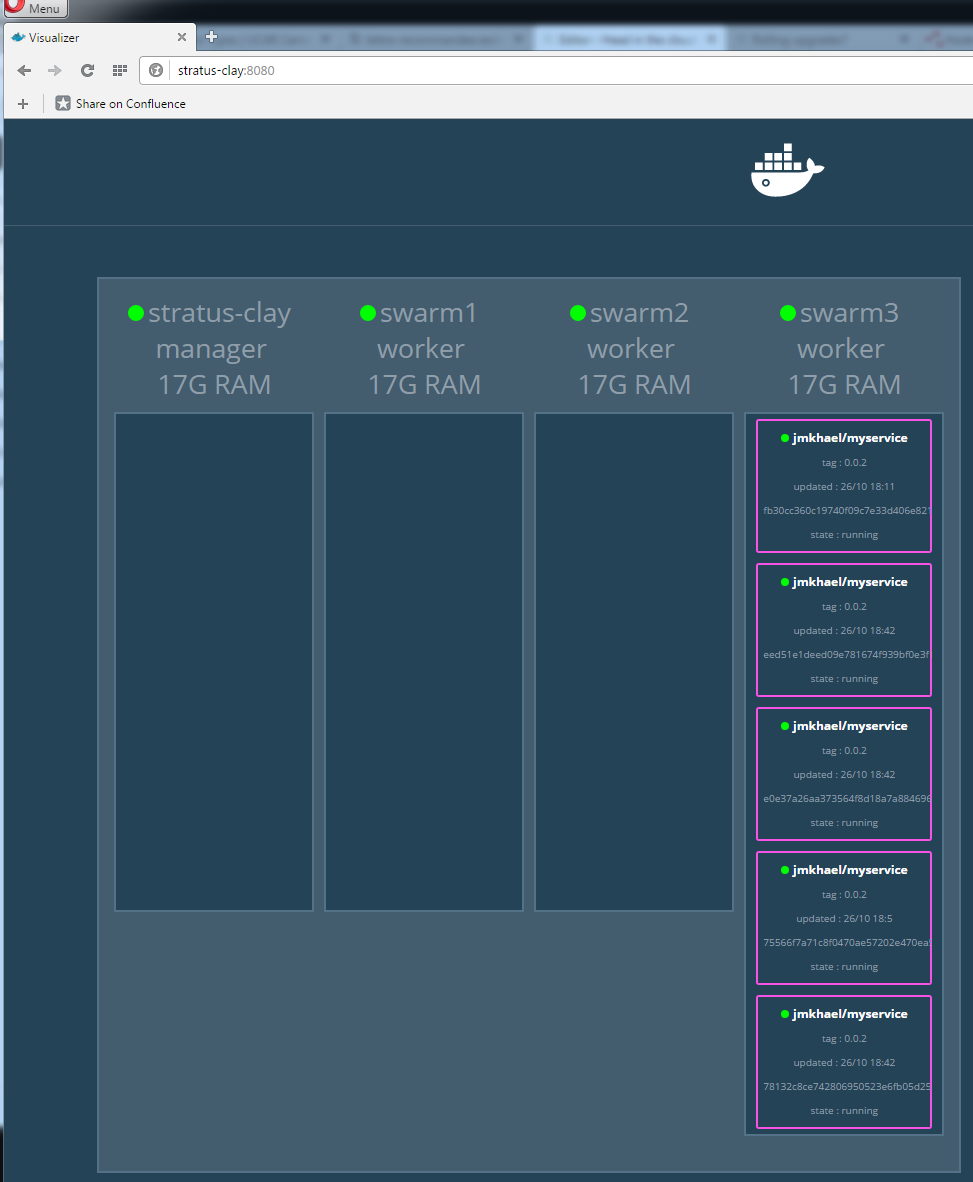
Docker moved all the containers to the remaining node transparently!
What's Next?
What we saw here in action is practically the rolling upgrades feature. We've touched on cluster management a bit and saw the Visualizer.
In next posts we probably will see how shipyard can help accelerate the introduction of Ops in the equation.
(A future post may bring a way to integrate all this from a Jenkins pipeline.)
Stay tuned.